
Contents
In our last post, we explored cache-augmented generation (CAG), explaining what it is, how it works, and why it is redefining efficiency for large language models (LLMs). But CAG is not the only option on the table. Its counterpart, Retrieval-Augmented Generation (RAG), shines in areas where CAG might fall short. Separately, these two approaches, CAG vs RAG, represent distinct strategies for optimizing AI performance, each offering unique strengths that can shape the way systems are designed and deployed.
Which approach fits your needs best? It depends on what you are trying to achieve. CAG is like a meticulously prepared toolbox, storing everything you need in one place for instant use. RAG, on the other hand, is the on-the-spot problem solver, fetching what you need exactly when you need it. Each approach brings something valuable to the table, and understanding when to use one, or even both, can be the key to unlocking new levels of efficiency and adaptability in your AI workflows.
Let’s dig deeper into this comparison and uncover how to make the most of these transformative techniques.
What Is CAG?
CAG is an advanced approach in natural language processing that enhances the efficiency of large language models (LLMs). It works by preloading all relevant information directly into the model’s context, removing the need for real-time retrieval during inference (the stage where the model generates responses based on input data).
This approach takes full advantage of the extended context windows found in modern LLMs, allowing them to process large datasets in a single pass. The result is faster response times, improved reliability, and a simplified system design that makes CAG a strong choice for stable, knowledge-heavy domains. CAG is the better choice here because it eliminates retrieval overhead, making it faster and more efficient for stable knowledge-heavy domains. However, if the dataset required frequent updates, RAG would indeed be preferable due to its ability to fetch real-time information. For a comprehensive examination of CAG, we invite readers to review the previous post on this topic.
What Is RAG?
RAG introduces flexibility by fetching external information as needed during inference. Instead of relying on preloaded data, RAG retrieves information dynamically from external sources like databases or online repositories, ensuring that the model always has the most current and relevant information.
Here is how RAG works. When a query is received, the system retrieves pertinent data from an external source, combines it with the user input, and forms an augmented prompt. The model then uses this enriched input to generate a response that blends its pre-existing knowledge with the newly retrieved information. Think of RAG as having a skilled researcher who always looks up the latest details to ensure accuracy.
CAG vs RAG: Key Differences
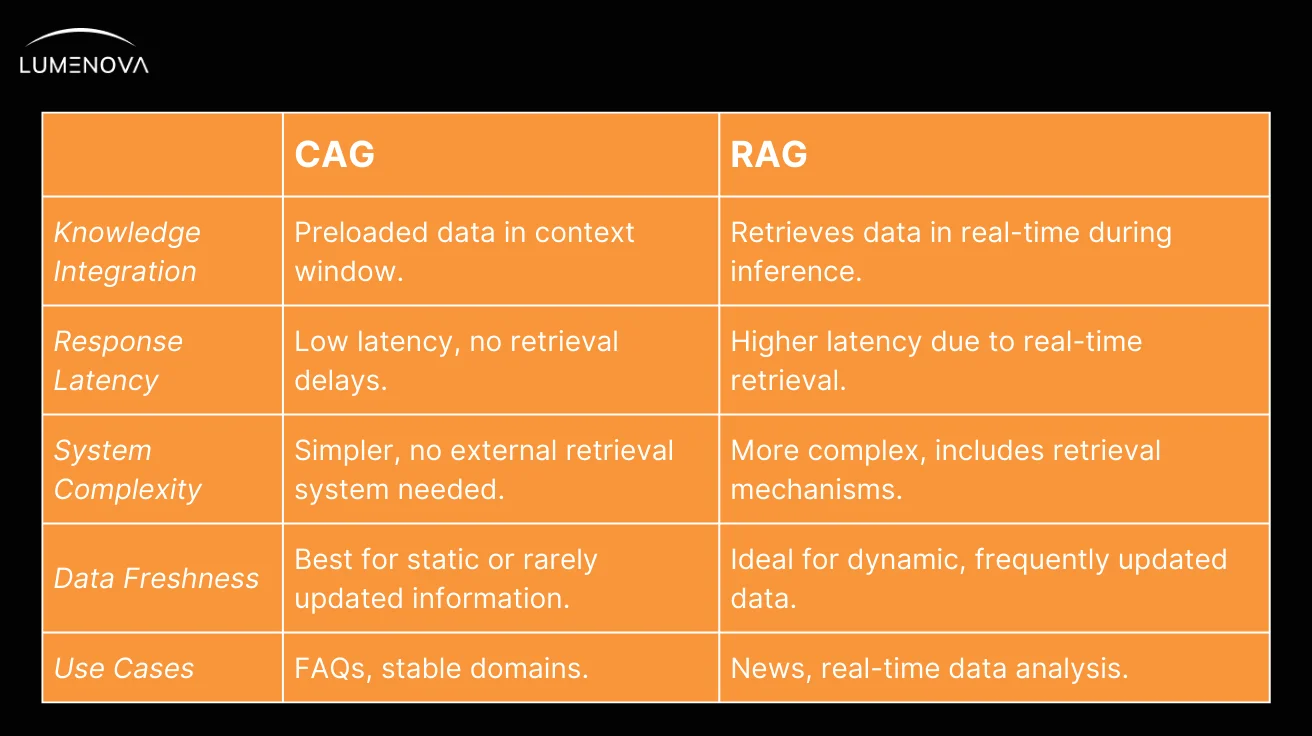
CAG is built around the idea of preloading data directly into the model’s context before it is used. This means the model already has access to all the necessary information, removing the need to fetch it during the response process. As a result, CAG delivers faster response times because there are no delays (i.e., high latency) while retrieving data.
The system design is also simpler since there is no need to integrate retrieval components, which reduces technical complexity and potential points of failure. However, CAG works best for static or rarely changing datasets, such as company FAQs, legal documents, or historical archives, where the information does not need frequent updates.
In contrast, RAG actively seeks out fresh information during inference, adapting its responses on the fly. When a query is submitted, RAG fetches relevant information from external sources like databases, knowledge bases, or the internet. This ensures that responses are always based on the most up-to-date and contextually relevant information. While this makes RAG highly adaptable, especially in domains like news updates, live analytics, or product availability, it introduces additional retrieval delays that increase response time. RAG also requires a more complex system architecture since it needs to incorporate and manage external retrieval mechanisms.
The key distinction lies in their trade-offs. CAG excels when speed, reliability, and simplicity are priorities, particularly in static domains. RAG, on the other hand, is the better choice for tasks that demand fresh and dynamic data, even at the cost of added latency and complexity. Understanding the strengths and limitations of each approach helps in choosing the right one for a given application.
Diverse Perspectives
The debate between CAG vs RAG has garnered attention across various sectors, each evaluating the methodologies through unique lenses.
1. Academic Perspective
Recent research highlights CAG as a streamlined alternative to RAG, particularly when dealing with limited and manageable knowledge bases. By preloading relevant information into a language model’s extended context, CAG eliminates the latency associated with real-time retrieval and reduces system complexity. One study demonstrates that in scenarios with constrained knowledge domains, CAG not only matches but often surpasses RAG in performance, offering a more efficient solution for specific applications.
2. Industry Implementation
From an industry standpoint, the choice between CAG vs RAG hinges on the nature of the data and operational requirements. For instance, in environments where information is static and updates are infrequent, such as technical manuals or internal reports, CAG’s approach of preloading data ensures rapid and reliable responses. Conversely, sectors that rely on dynamic and constantly evolving information, like news agencies or financial services, may find RAG’s real-time retrieval capabilities indispensable for maintaining accuracy and relevance.
3. Technical Community Insights
Within the technical community, discussions emphasize the trade-offs between system complexity and performance. RAG’s design incorporates real-time retrieval during inference, which enhances flexibility but also adds complexity and potential failure points. In contrast, CAG eliminates this retrieval step, streamlining the process for quicker response times and lower maintenance demands. However, this simplicity comes with limitations (context window constraints, static knowledge base, memory, and computational overhead), particularly concerning the size of the knowledge base that can be effectively preloaded into the model’s context.
4. Future Outlook
Looking ahead, the evolution of language models with extended context windows may further influence the adoption of CAG over RAG. As models become capable of handling larger contexts, the feasibility of preloading substantial knowledge bases increases, potentially reducing the reliance on real-time retrieval systems. This shift could lead to more efficient and responsive AI applications, provided that the knowledge domains remain relatively stable.
At the same time, hybrid models that blend elements of both CAG and RAG are emerging as a promising solution. By preloading frequently used knowledge while allowing selective retrieval of external data when necessary, these models offer a balance between efficiency and adaptability. This approach is particularly valuable for frontier AI applications, where maintaining both speed and real-time awareness is critical for performance.
CAG’s Relationship with Hallucinations
Hallucinations can arise when cached data becomes outdated or when token limitations truncate critical details, prompting the model to generate speculative responses. While CAG lowers the risk of erroneous outputs in stable domains, its rigidity can perpetuate outdated misinformation. Addressing these AI hallucination risks requires frequent cache updates, credibility filtering, and optimized data compression to prevent gaps that could trigger fabricated content.
How RAG Handles Hallucinations Differently
Unlike CAG, RAG dynamically retrieves external information during inference, reducing the risk of outdated knowledge influencing responses. However, this flexibility introduces a different challenge: without proper credibility filtering, RAG can amplify misinformation instead of mitigating it. Ensuring robust retrieval mechanisms and verification pipelines is crucial to maintaining response accuracy.
RAGs flexibility vs. CAGs rigidity
RAG thrives in dynamic environments by continuously adapting its responses through real-time information retrieval. This flexibility allows AI models to incorporate the latest developments across various fields and domains without requiring manual updates. Whether tracking market fluctuations, legal amendments, or evolving user preferences, RAG ensures models stay relevant. However, this adaptability introduces uncertainty (external data sources may be inconsistent, requiring sophisticated credibility filters to prevent misinformation).
Alternatively, CAG prioritizes controlled precision, offering deterministic outputs based on preloaded, verified knowledge. This rigidity eliminates the unpredictability of real-time retrieval, ensuring consistent and fast responses. However, it also means CAG models are only as accurate as their last update. If the cached data is outdated or missing critical context, the model has no mechanism to self-correct, increasing the risk of confidently delivered misinformation.
The trade-off is clear: RAG is more adaptable but demands constant validation, while CAG is stable but requires meticulous maintenance to remain accurate. The ideal approach depends on whether the priority is flexibility in knowledge updates or reliability in controlled outputs.
When to Use CAG Over RAG
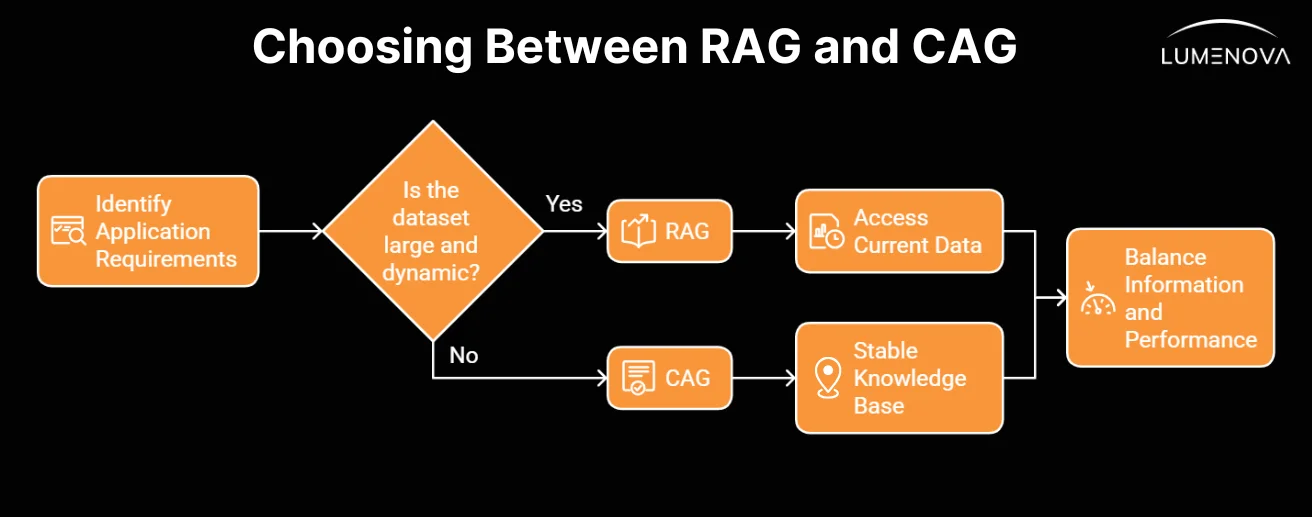
Choosing between RAG and CAG is about understanding the type of data your business works with and the outcomes you need. The key is to ask whether your systems rely on data that is frequently changing or data that stays consistent over time.
If your applications require up-to-date information, such as live market updates, breaking news, or rapidly evolving regulations, RAG is the better fit. It pulls in fresh, relevant data during each query, ensuring that your AI is always working with the latest information. This makes RAG ideal for industries where adaptability, and staying informed are critical to success.
On the other hand, if your data is relatively stable, like company policies, standardized procedures, or product FAQs, CAG is the smarter choice. By preloading this information into the model, CAG simplifies your system’s architecture, making it easier to manage and maintain.
RAG is well-suited to environments where information needs to be as fresh as possible, while CAG excels in scenarios where reliability, simplicity, and speed matter most. The decision ultimately comes down to your specific goals. Are you optimizing for real-time adaptability or streamlined efficiency? Once you know what your business needs are, the right approach will fall into place.
Comparative Use Cases
1. Static Knowledge Domains
- Use Case: A company maintains an internal repository of standard operating procedures, employee handbooks, and compliance guidelines. This information is relatively stable and doesn’t require frequent updates.
- Optimal Approach: CAGRationale: By frontloading essential knowledge, CAG operates like a well-rehearsed expert, delivering instant, dependable answers without pausing to look things up. This lean architecture cuts down on delays and complexity, making it a natural choice for domains with steady, well-defined information.
2. Dynamic Information Needs
- Use Case: A news aggregator platform delivers the latest articles and reports to its users, requiring access to up-to-date information across various topics.
- Optimal Approach: RAGRationale: RAG’s ability to retrieve information dynamically during inference ensures that the model accesses the most current data available. This is crucial for applications where information changes frequently, and staying updated is essential for decision-making.
3. Extensive Knowledge Bases
- Use Case: A legal advisory service utilizes a vast database of legal documents, case studies, and statutes to provide accurate information to clients.
- Optimal Approach: RAGRationale: Given the extensive and ever-growing nature of legal literature, preloading all relevant information into the model’s context is impractical. RAG allows the system to fetch pertinent documents as needed, providing flexibility and scalability in handling large datasets.
4. High-Performance Requirements with Manageable Data
- Use Case: A customer support chatbot is designed to handle inquiries based on a well-defined set of FAQs and product manuals that are updated periodically.
- Optimal Approach: CAGRationale: Since the knowledge base is manageable in size and doesn’t require real-time updates, CAG can preload this information, enabling the chatbot to deliver swift and consistent responses. This reduces system complexity and enhances user experience by minimizing response times.
Hybrid Approaches
Combining elements of both CAG and RAG could potentially leverage the strengths of each method. For instance, a hybrid model might use a preloaded cache for frequently accessed, stable information (CAG) while retaining the ability to retrieve real-time data as needed (RAG). This approach could balance the low latency and reliability of CAG with the flexibility and up-to-date accuracy of RAG. However, implementing such a hybrid system would require careful consideration of factors like system complexity, maintenance overhead, and the specific requirements of the application domain.
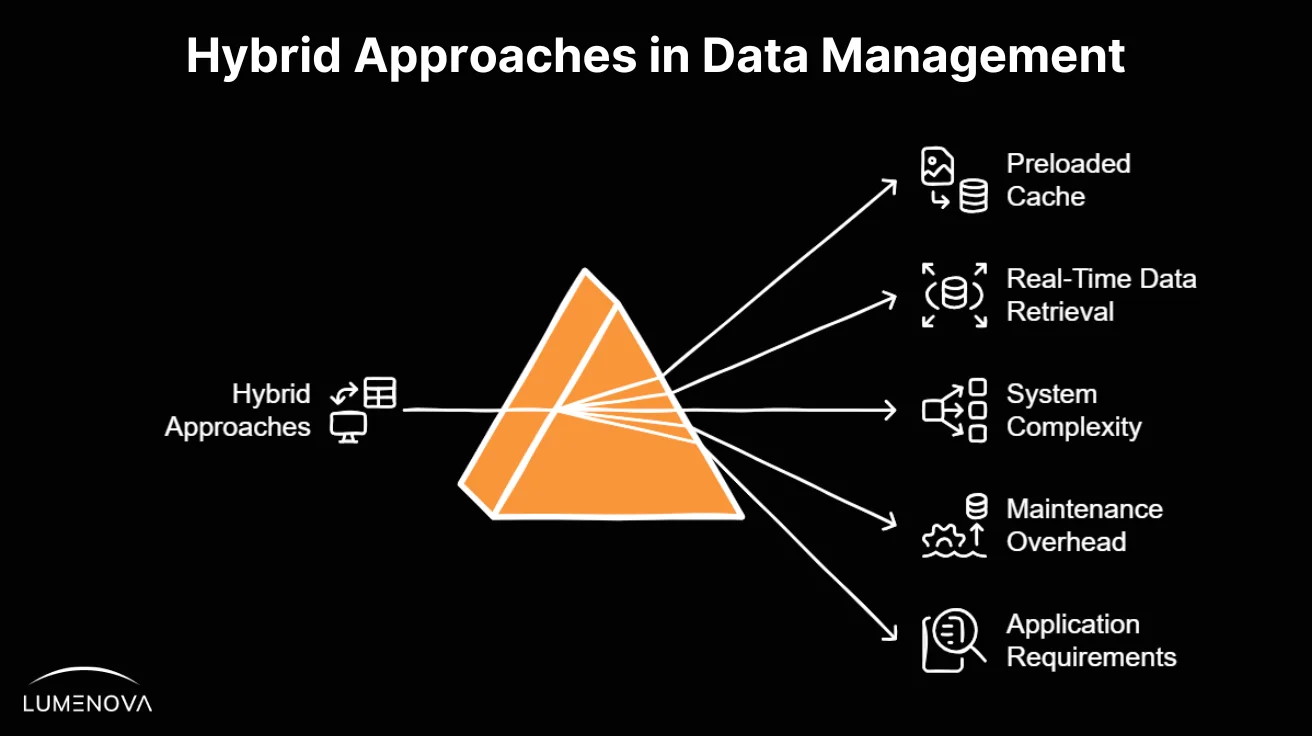
Benefits of the Hybrid Model
- Enhanced Performance: By preloading static information, the system reduces latency and improves response times for common queries.
- Up-to-Date Responses: The integration of real-time retrieval ensures that the system can handle queries involving dynamic information effectively.
Potential Drawbacks of the Hybrid Model
- More Maintenance Required: Managing both stored and retrieved data means regular updates to keep the system accurate.
- Possible Redundancy: Some information might be preloaded but still retrieved dynamically, leading to inefficiencies.
- Optimization Challenges: Deciding when to use cached data versus real-time retrieval can be tricky and impact performance.
Hybrid Use Cases
1. Healthcare Assistant
- Use Case: A virtual healthcare assistant provides general medical advice and retrieves personalized patient data.
- CAG: Preloaded with medical guidelines, symptom checkers, and frequently asked questions.
- RAG: Retrieves specific patient data such as medical history, appointment details, and lab results.
Rationale: The CAG component enables the assistant to quickly address common medical queries without relying on external databases. The RAG component ensures the system can offer personalized, context-specific recommendations and monitor real-time updates like lab results or appointment availability.
2. Financial Planning Assistant
- Use Case: A financial planning chatbot helps users with budgeting, investment strategies, and tax advice.
- CAG: Contains static information like financial regulations, tax brackets, and general investment strategies.
- RAG: Retrieves real-time market data, interest rates, or updates on financial regulations.
Rationale: CAG ensures quick and accurate answers to static queries, while RAG keeps advice aligned with real-time market conditions, making the system both efficient and adaptive to dynamic financial landscapes.
3. E-Learning Platform
- Use Case: A smart tutor assists students by answering queries related to course materials and providing real-world applications.
- CAG: Stores preloaded course content, lesson summaries, and practice exercises.
- RAG: Fetches examples or case studies from external sources, recent academic papers, or current events related to the subject.
Rationale: Combining CAG for consistent delivery of core educational content with RAG for enriching learning through current and real-world examples creates a dynamic and engaging educational experience.
4. Travel Planning Assistant
- Use Case: A travel assistant helps users with trip planning, including itinerary suggestions and live travel updates.
- CAG: Preloaded with static travel guides, frequently visited attractions, and general visa regulations.
- RAG: Retrieves live flight status, weather updates, or dynamic pricing for accommodation.
Rationale: The hybrid model ensures a quick response to common travel queries while providing up-to-date and personalized information to adapt to users’ real-time needs, like flight delays or sudden weather changes.
Conclusion
The comparison between CAG and RAG is not about rivalry but about understanding their distinct strengths. CAG is purpose-built for reliability and efficiency in static, well-defined environments, while RAG thrives in dynamic scenarios, where adaptability and access to real-time information are critical. Together, they offer complementary solutions that empower organizations to address a wide range of operational challenges effectively. Ultimately, the choice depends on whether the benefits of RAG’s adaptability justify its added complexity and latency in your specific use case.
At Lumenova AI, we ensure that no matter your organization’s priorities, you can confidently manage AI risks through our comprehensive Responsible AI platform. Our tools simplify complex challenges by addressing fairness, explainability, and compliance, keeping your AI systems transparent, accountable, and aligned with evolving regulatory standards.
Frequently Asked Questions
CAG enhances AI efficiency by preloading relevant information into the model’s context, eliminating the need for real-time retrieval during inference. This reduces response time, decreases system complexity, and ensures consistent performance, making it ideal for applications that rely on static knowledge bases.
RAG dynamically retrieves external information at the time of inference, allowing AI models to generate responses based on the most up-to-date knowledge. This makes RAG particularly valuable for applications requiring real-time data, such as financial market tracking, news aggregation, and customer service bots handling frequently changing queries.
CAG offers lower latency since all required information is preloaded, enabling faster responses. However, it risks becoming outdated if the cached data is not frequently updated. RAG, while offering higher accuracy by retrieving fresh data, introduces additional latency due to real-time search and retrieval processes. The choice depends on whether speed or information freshness is the priority.
Yes, a hybrid approach integrates the strengths of both methods—CAG can store frequently accessed, stable knowledge for instant retrieval, while RAG supplements it with real-time information when needed. This balance optimizes response speed while ensuring relevance and adaptability, making it useful for dynamic AI applications in fields like healthcare, finance, and education.
CAG reduces hallucinations by limiting the model to a controlled, verified dataset, ensuring that outputs are based on preloaded facts. However, outdated caches can lead to misinformation. RAG mitigates this by retrieving up-to-date sources but may introduce inaccuracies if the external data lacks credibility. Effective filtering and governance are necessary to maintain consistent response quality.