February 4, 2025
CAG: What Is Cache-Augmented Generation and How to Use It

Contents
What if your AI systems could deliver faster responses, operate with greater reliability, and require less technical maintenance? This is the promise of cache-augmented generation (CAG), a cutting-edge approach that reimagines how large language models (LLMs) handle information.
For businesses, the potential impact of CAG is profound. Faster response times transforms customer interactions; improved reliability ensures consistent results;simpler system architecture reduces overhead and operational challenges. It is a solution designed to meet the growing demand for AI systems that are both powerful and practical.
In this post, you will learn what CAG is, how it works, and the opportunities it creates for organizations across industries.
Understanding CAG
CAG is an innovative approach that enhances the efficiency of LLMs by preloading all pertinent information into the model’s context, thereby eliminating the need for real-time data retrieval. This method leverages the extended context windows of modern LLMs, allowing them to process substantial amounts of information in a single inference step.
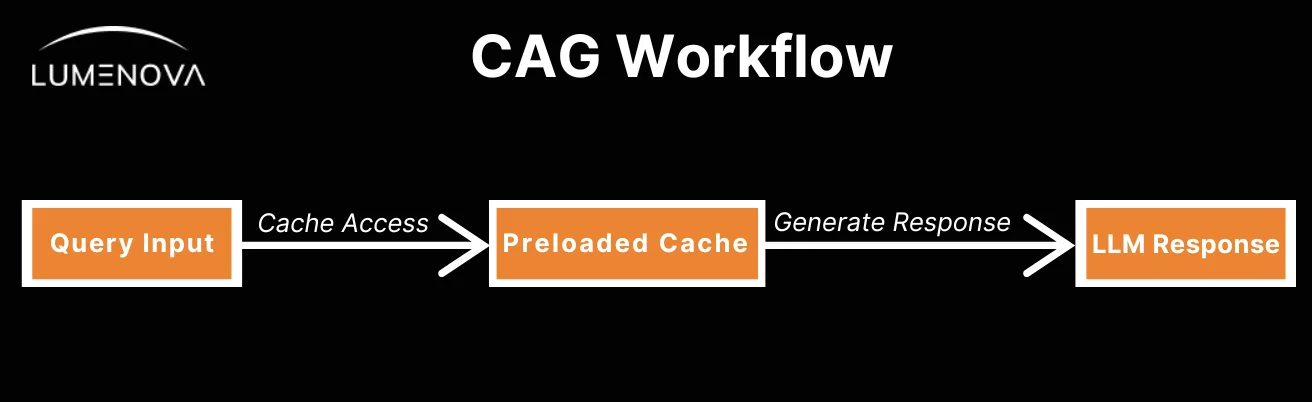
You can think of CAG as a well-organized desk. Before you start working, you place all the important notes and documents within reach. When you need information, you grab it instantly instead of searching through books or online sources. CAG does the same for AI by preloading relevant data so responses are faster and more reliable.
How CAG Works
The CAG framework operates through three key stages:
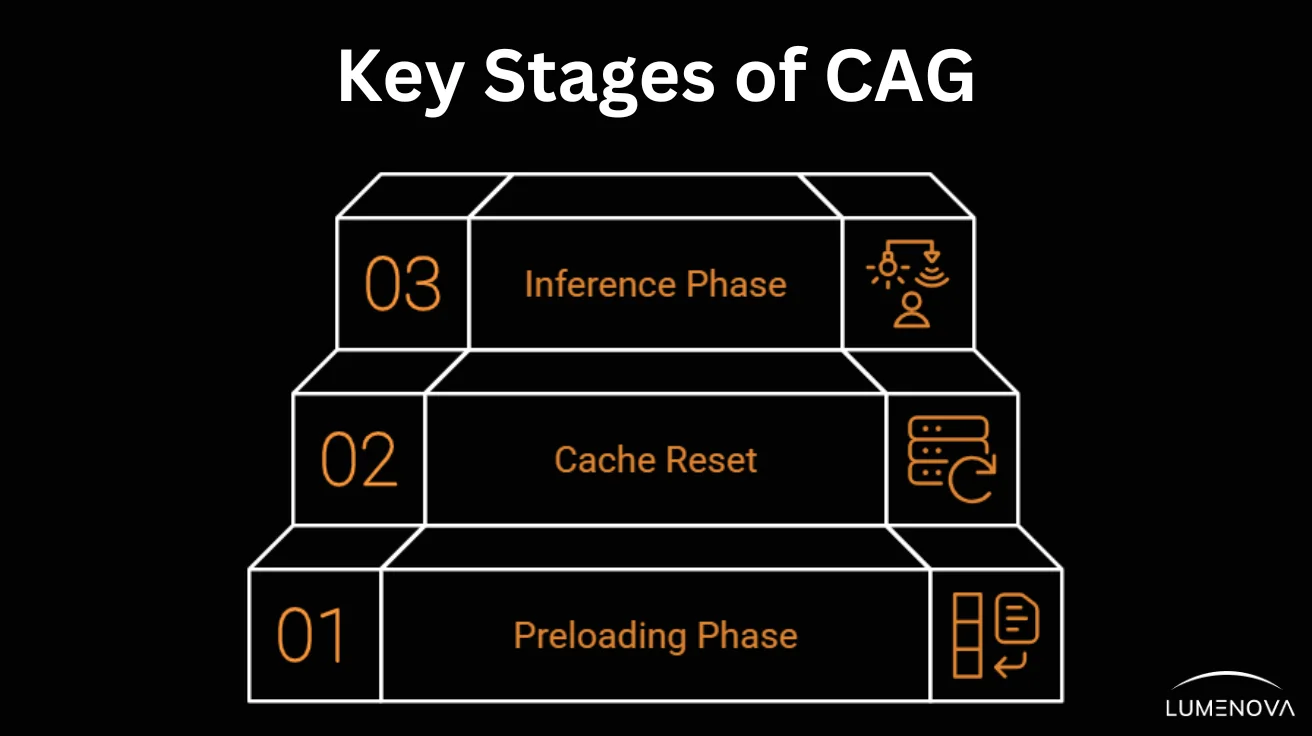
- Preloading Phase: Relevant documents are preprocessed and stored within the model’s extended context window, creating a cache of essential knowledge accessible during inference.
- Cache Reset: At the beginning of each session, the cache is reset to maintain system readiness and ensure that responses are based on fresh, relevant context.
- Inference Phase: When a user query is received, the model utilizes the precomputed cache to generate responses directly, bypassing the need for real-time retrieval and enabling fast, coherent outputs.
Advantages of CAG
CAG introduces a range of compelling advantages that significantly enhance the efficiency, reliability, and security of AI workflows. These benefits position CAG as a powerful solution for organizations seeking to optimize their use of LLMs.
1. Faster Response Times
One of the most compelling advantages of CAG is its ability to deliver near-instantaneous responses by preloading all necessary data into the model’s context. Unlike traditional systems that rely on real-time retrieval, which can introduce delays as the system fetches and processes external data, CAG eliminates this step entirely.
This preloading ensures that the model has immediate access to the information it needs, resulting in significantly reduced latency and a more seamless user experience. For instance, in customer service applications, this means users receive prompt and accurate responses without the typical wait times associated with data retrieval processes.
2. Higher Reliability
Preloading data into the model ensures that the system works with a curated and comprehensive knowledge base, reducing the risk of errors associated with document selection or retrieval. This makes responses more consistent and dependable, especially in scenarios where accuracy is critical.
By having all relevant information readily available within the model’s context, CAG minimizes the chances of retrieving outdated or irrelevant data, thereby enhancing the overall reliability of the system. This is particularly beneficial in fields like healthcare or legal services, where the accuracy and relevance of information are paramount.
3. Simplified Architecture
By removing the need for external sources, CAG simplifies the overall system design. Traditional retrieval-based architectures often require databases, APIs, and integration layers, each of which introduces potential points of failure and increases maintenance overhead.
CAG’s streamlined approach reduces these complexities, leading to a more robust and maintainable system. This simplification not only lowers the likelihood of technical issues but also reduces the resources needed for system upkeep, allowing organizations to allocate their efforts more efficiently.
4. Enhanced Security
CAG also offers significant security advantages by keeping sensitive data internal. In retrieval-based systems, data often needs to be fetched from external sources, which increases exposure to potential breaches.
With CAG, the preloaded cache remains within the AI system, reducing vulnerability to cyber threats and bolstering compliance with data privacy regulations. Keeping data confined to a secure, internal system is crucial for industries handling confidential information, such as finance or healthcare, minimizing the risk of unauthorized access during data transmission.
When to Use CAG
CAG is most effective in:
- Applications Requiring Rapid Responses: Useful where quick answers are crucial, like customer service.
- Security-Sensitive Environments: Protects confidential data by avoiding external retrieval during sensitive operations.
- High-Volume, Repetitive Queries: Efficient for systems handling repetitive questions or actions.
- Hybrid Scenarios: In cases where both preloaded and real-time data are needed, CAG can combine static knowledge with dynamic retrieval. This approach is particularly useful in industries like finance and healthcare, where regulations, market trends, or medical guidelines are frequently updated.
CAG Use Cases by Industry
CAG’s unique approach of preloading static, high-utility datasets can optimize workflows across various industries. Below is a detailed overview of how CAG can transform these sectors with clearly labeled examples:
Banking & Investment
CAG can enhance financial decision-making by preloading foundational knowledge, such as general investment principles, historical market trends, and compliance guidelines, while dynamically retrieving real-time market data.
Example: When a client requests an investment strategy, the AI can immediately analyze the client’s portfolio and suggest personalized investment opportunities based on preloaded financial principles and recent market patterns, saving time and boosting client trust.
Consumer Goods
Preloading product specifications, past customer interactions, and sales trends allows AI systems to provide quick responses, while real-time retrieval helps adapt to inventory fluctuations and evolving customer preferences.
Example: An online retailer’s chatbot could instantly suggest items based on a customer’s browsing history and available inventory, while also offering discounts tied to ongoing campaigns, creating a tailored shopping experience and optimizing inventory management.
Healthcare & Life Sciences
CAG can preload medical guidelines, drug information, and treatment protocols, ensuring rapid access to validated medical knowledge.
Example: A rural clinic without specialist access can input patient symptoms, and the AI, using preloaded diagnostic protocols, can recommend treatments or flag cases for further review, significantly improving healthcare delivery in underserved areas.
Human Resources & Recruitment
CAG preloads job descriptions, hiring criteria, and compliance guidelines.
Example: A recruiter can use AI to quickly match candidates’ resumes to job requirements, generating shortlists in minutes while ensuring compliance with labor laws, thereby reducing hiring timelines and increasing efficiency.
Insurance
CAG systems can preload customer policies and standardized claim processing rules while dynamically retrieving real-time claim histories and risk assessments to ensure accurate evaluations.
Example: In auto insurance, a customer’s claim for minor damages can be automatically approved by cross-referencing preloaded policy details, enabling instant settlement for low-risk claims and improving customer satisfaction.
Technology & IT Support
Preloading troubleshooting protocols and system logs allows IT support bots to diagnose issues instantly.
Example: If a user reports a system crash, the AI can cross-reference the preloaded logs and suggest solutions or escalate unresolved problems, reducing downtime and ensuring business continuity.
Telecommunications
Preloaded network configurations, historical tickets, and performance metrics enable proactive problem-solving.
Example: AI can predict and alert users about potential connectivity issues before they occur, based on analysis of preloaded data combined with real-time performance monitoring, minimizing disruptions.
Utilities
With preloaded historical weather patterns, energy consumption data, and grid configurations, CAG helps utility companies optimize resource allocation.
Example: During a heatwave, preloaded data can assist in predicting peak energy demand, allowing the grid to adjust and prevent blackouts while improving renewable energy utilization.
How to Implement CAG
Implementing CAG involves several critical steps to ensure optimal performance and reliability.
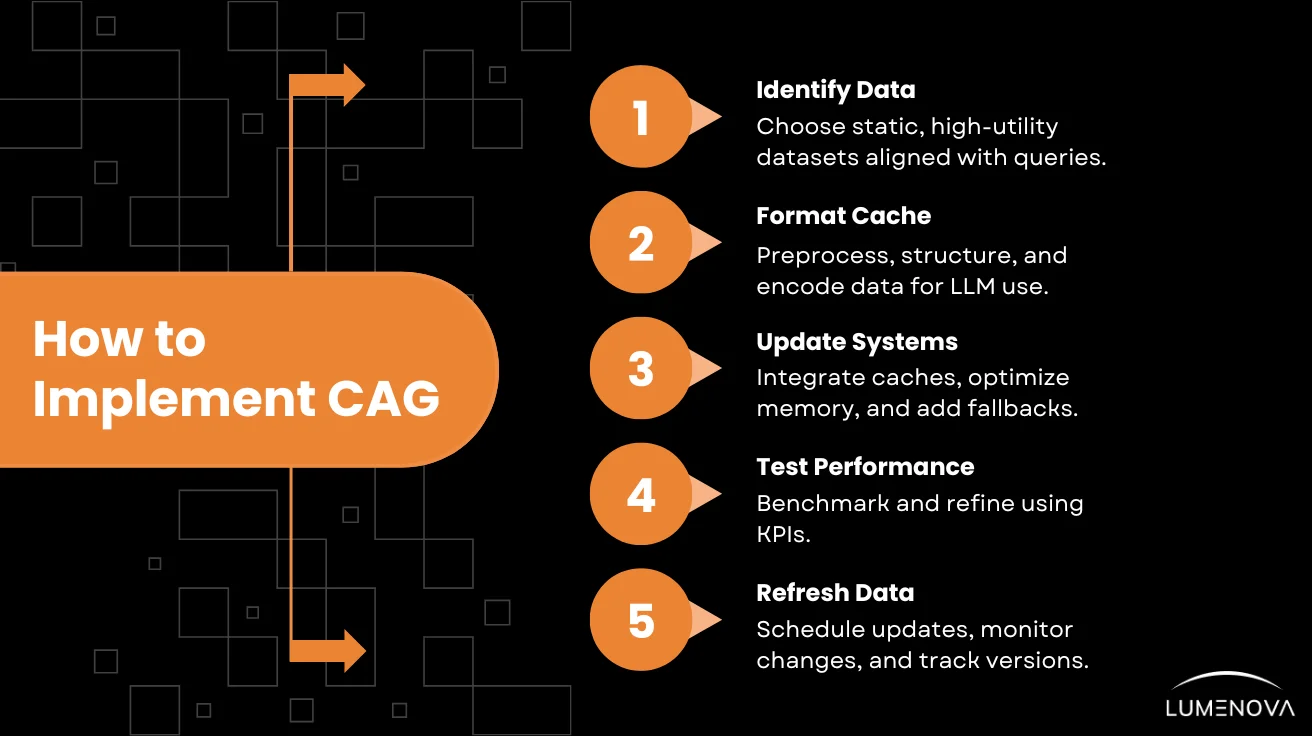
1. Identifying Static and High-Utility Data for Preloading
- Data Selection: Identify datasets that remain stable over time and do not require frequent updates, such as company policies, product manuals, or industry regulations. Avoid preloading rapidly changing data like real-time stock prices or user-generated content.
- Relevance Assessment: Ensure the preloaded data is directly relevant to common user queries, minimizing unnecessary information while maximizing the likelihood of retrieval during inference.Checklist for Selecting Preloaded DataWhen deciding what data to preload in a CAG system, consider the following criteria:
- Consistency Over Time: Does the data remain stable, with minimal updates? (e.g., compliance guidelines, historical case studies)
- High Utility & Frequency: Is the data frequently referenced by users? (e.g., product specifications, standard troubleshooting steps)
- Latency Reduction: Would preloading this data significantly reduce response time compared to real-time retrieval?
- Complementary to Real-Time Data: Can this data be effectively combined with dynamic retrieval for a hybrid approach? (e.g., preloading medical guidelines while retrieving patient records in real time)
- Security & Compliance: Does preloading this data improve privacy and security by reducing the need for external calls?
2. Formatting and Curating the Cache for Integration
- Automating Data Preprocessing for CAG
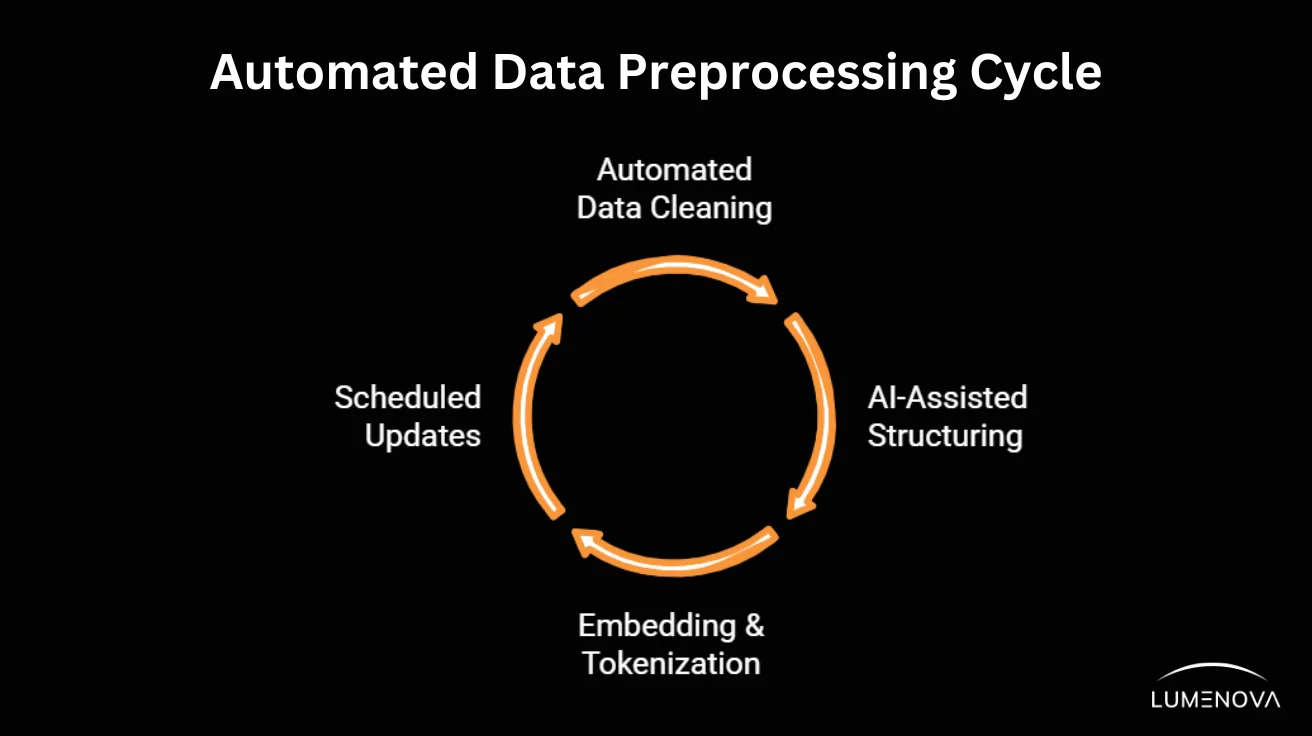 Manually curating and structuring data for preloading can be time-intensive, but AI-driven tools can help:
Manually curating and structuring data for preloading can be time-intensive, but AI-driven tools can help:
- Automated Data Cleaning: AI-powered pipelines remove redundancies, correct errors, and standardize formats.
- AI-Assisted Structuring: NLP-based tools organize text into structured formats optimized for LLM context windows.
- Embedding & Tokenization Tools: Many AI frameworks (e.g., OpenAI, Hugging Face) offer built-in methods to convert text into preprocessed embeddings.
- Scheduled Updates: Automation ensures that preloaded data is periodically refreshed without manual intervention.
By leveraging these automation techniques, organizations can streamline CAG implementation while maintaining high data accuracy and relevance.
- Structuring Data: Organize the data to fit within the LLM’s context window. This involves segmenting the information into manageable chunks and encoding it appropriately.

- Encoding: Utilize tokenization and embedding techniques compatible with your LLM to convert the preprocessed data into a format suitable for integration.
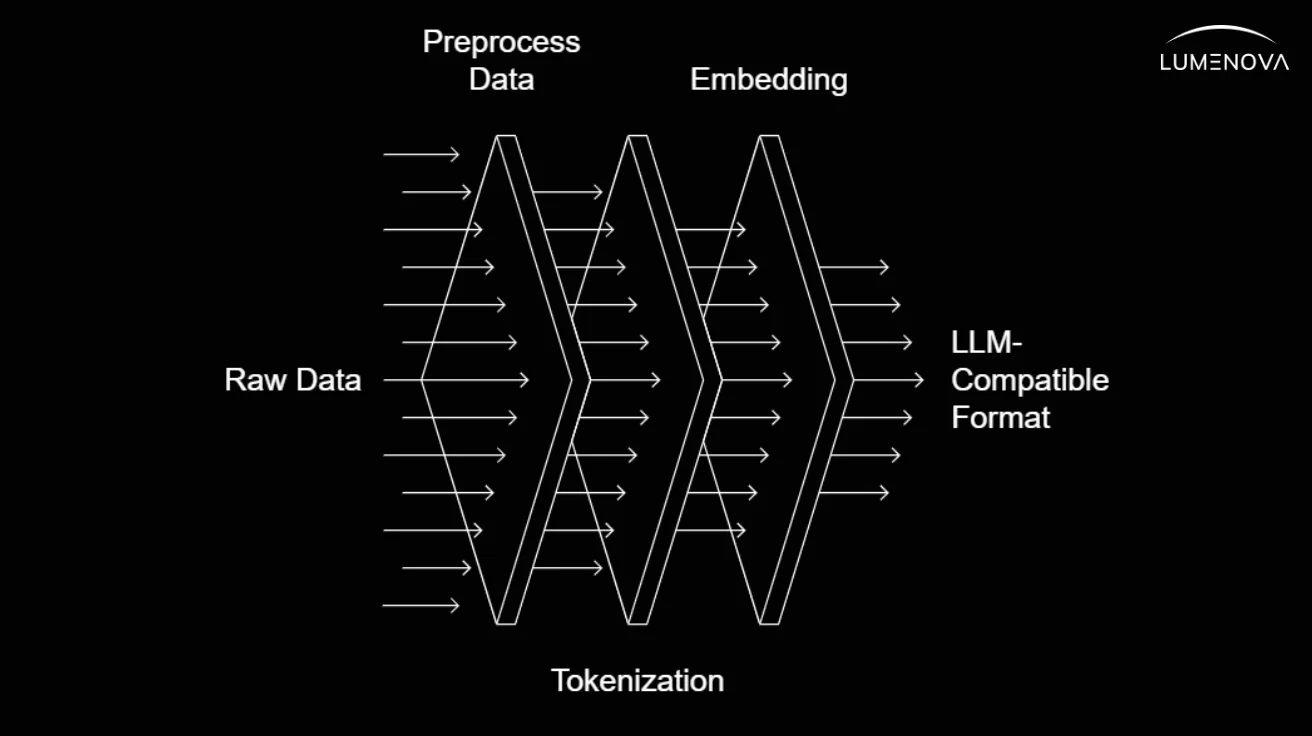
3. Updating System Architecture to Support Preloaded Contexts
- Integration of key-value (KV) Cache: Modify your system architecture to accommodate the preloaded contexts by integrating mechanisms to load the precomputed key-value (KV) cashes into the model during initialization.Think of this key-value (KV) cache like a digital filing cabinet. Instead of searching through a massive database every time, the system preloads the most relevant information in an easy-to-access memory slot, ensuring faster response times. To implement this, your architecture needs mechanisms to store and retrieve this precomputed cache during initialization.
- Memory Management: Ensure that the system’s memory allocation can handle the additional load of the preloaded data without performance degradation.
- Fallback Mechanisms: Implement fallback procedures to handle scenarios where the preloaded data may not cover specific queries, maintaining system robustness.
4. Testing and Validating Model Performance
- Performance Metrics: Define key performance indicators (KPIs) such as response accuracy, consistency, and latency to evaluate the model’s effectiveness with the preloaded data.
- Benchmarking: Utilize benchmark datasets and real-world scenarios to assess how well the model handles various queries.
- Iterative Testing: Conduct thorough testing to validate the model’s performance, identifying potential issues and optimizing the system through iterative refinement.
5. Regularly Refreshing Cached Data for Accuracy and Relevance
- Scheduled Updates: Establish a schedule for reviewing and updating the cached data to incorporate any changes or additions, ensuring the information remains accurate and relevant.
- Automated Monitoring: Implement automated monitoring tools to detect when updates are required, maintaining the integrity and usefulness of the preloaded information.
- Version Control: Maintain version control over the cached data to track changes and ensure consistency across updates.
Our trusted AI Platform could support CAG implementation through data quality checks, such as detecting biases and addressing performance challenges like data drift. Our compliance tools help organizations stay aligned with evolving regulatory standards, fostering trust and transparency in AI operations.
Challenges in Using CAG
While CAG offers notable advantages, its implementation presents several challenges that organizations must address to ensure effective implementation:
- Managing Limitations in Model Context Windows: Despite advancements in LLMs featuring extended context windows, these models still have a finite limit on how much data can be preloaded. Current frontier AI models typically support context windows ranging from 32,000 to 100,000 tokens, depending on the architecture. When the required knowledge base exceeds this limit, it becomes challenging to include all pertinent data, potentially leading to incomplete responses.This limitation necessitates careful selection and prioritization of information to preload, ensuring that the most critical data is available within the context window. Additionally, strategies such as summarization or data compression may be employed to maximize the utility of the available context space.
- Ensuring Preloaded Knowledge Remains Current: CAG relies on preloaded data, which can become outdated if not regularly maintained. In dynamic fields where information changes frequently, CAG is most effective when combined with retrieval-based methods, ensuring that responses incorporate both static knowledge and the latest updates.
- Handling Scalability for Larger Datasets or Hybrid Systems: As the size of knowledge bases grows, relying solely on CAG becomes impractical due to context window limitations. Hybrid approaches offer a scalable solution that balances efficiency with accuracy. These methods allow AI systems to quickly access foundational knowledge while dynamically retrieving the latest updates when needed.Examples of Hybrid CAG Implementationsa. Financial Advisory AI
- Preloaded Data: Investment principles, tax regulations, historical market trends.
- Real-Time Retrieval: Live stock prices, economic reports, client portfolio updates.
- How It Works: An AI-driven financial assistant suggests an investment strategy based on preloaded financial models but dynamically retrieves the latest market conditions to refine its recommendations.
b. AI-Powered Medical Assistant
- Preloaded Data: Standard treatment protocols, drug interaction guidelines, disease risk factors.
- Real-Time Retrieval: Patient history, lab test results, latest research publications.
- How It Works: A doctor inputs symptoms into an AI tool, which uses preloaded medical guidelines to suggest possible conditions. The system then retrieves the patient’s most recent test results to refine the diagnosis.
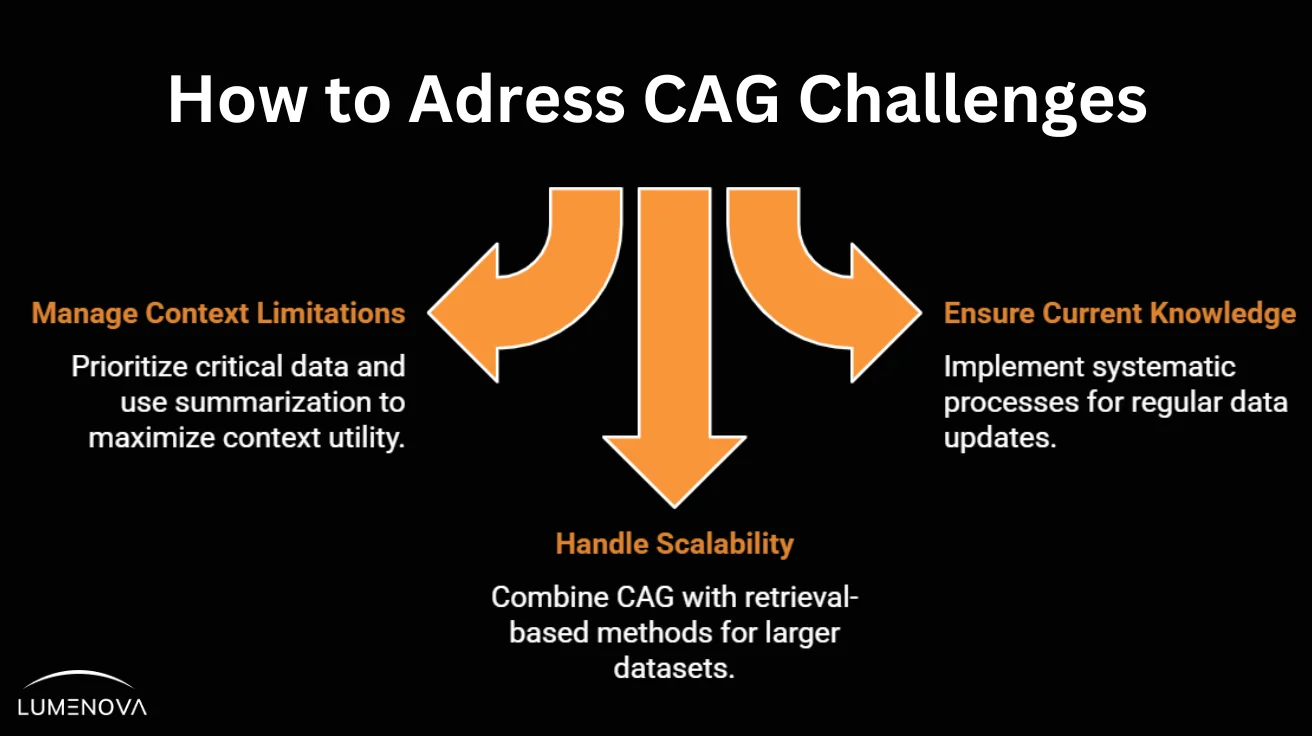
Addressing these challenges involves a combination of strategic planning, regular maintenance, and the adoption of flexible system architectures capable of integrating multiple data management approaches. By proactively managing context limitations, ensuring data relevance and designing for scalability, organizations can effectively leverage CAG to enhance their AI workflows.
Reflective Questions
- How could CAG’s faster response times and simplified architecture improve your current AI workflows?
- What types of static, high-value data in your organization could benefit most from preloading with CAG?
- What challenges might your organization face in maintaining the relevance and accuracy of preloaded CAG data?
Conclusion
CAG is flipping the script on how businesses use LLMs. Faster responses, more reliable outputs, simplified architectures, it’s all here. By embedding static, high-value data into a model’s context, CAG eliminates delays, boosts accuracy, and streamlines operations. And the payoff? Huge. From customer service to healthcare, industries that rely on precision and speed are reaping the benefits.
However, CAG is not a one-size-fits-all solution. While it excels in scenarios where frequently accessed knowledge remains stable, it may not be ideal for highly dynamic environments requiring real-time updates. In such cases, RAG or hybrid approaches that combine both methods may offer better adaptability. The key is choosing the right approach based on the specific needs of your AI system.
Next week, we’ll dive into a detailed comparison of CAG and RAG, exploring how their unique strengths and differences can shape AI strategies. We’ll also examine how combining these methodologies can unlock new levels of performance and adaptability through hybrid systems. If you’re curious about how AI can achieve the perfect balance between speed, precision, and flexibility, this is an article you won’t want to miss.
Visit our blog to expand your knowledge of the innovative approaches shaping the future of artificial intelligence. Understand how Lumenova AI’s Responsible AI platform can support your organization in deploying advanced, trustworthy, and scalable AI systems.
Frequently Asked Questions
Unlike traditional retrieval-based AI, which searches for relevant data at the time of each query, CAG preloads essential knowledge into the model’s context. This allows for faster responses, reduces dependency on external sources, and simplifies system maintenance, making it ideal for stable datasets that don’t require frequent updates.
Before deploying CAG, businesses should evaluate whether their knowledge base is relatively stable or dynamic. They must also consider model context window limitations, the feasibility of keeping cached data up to date, and potential trade-offs in flexibility compared to retrieval-based methods like RAG.
Maintaining accuracy in a CAG-based system requires a structured update process, including scheduled cache refreshes, automated data validation, and periodic human oversight. Organizations should also monitor performance metrics to detect when preloaded knowledge becomes outdated and requires revision.
Industries that rely on structured, high-utility knowledge bases—such as finance, healthcare, insurance, and legal services—gain the most from CAG. It enables rapid decision-making and ensures AI-driven responses remain consistent with established guidelines, policies, and regulations.
Yes, a hybrid approach combines CAG’s speed and efficiency with RAG’s adaptability. Businesses can use CAG for preloading static, frequently referenced information while leveraging RAG for real-time data retrieval when freshness is critical. This balance is particularly useful in dynamic fields like market analysis, research, and customer support.